

本文记录桌面端环境下对网页离线存储、备份、浏览的方法。
先决条件
具备以下实验环境:
- 桌面端操作系统、Chrome 浏览器
- Git 仓库
演示链接:https://learn.microsoft.com/zh-cn/windows-server/administration/windows-commands/route_ws2008
方案一:MHTML+Git 仓库
适用于普通用户的离线网页存储、浏览行为。
保存
快捷键 Ctrl+S保存网页,选择 单个文件,即可保存成 .mhtml格式。在此过程中可以自定义需要的文件名,便于后期检索。
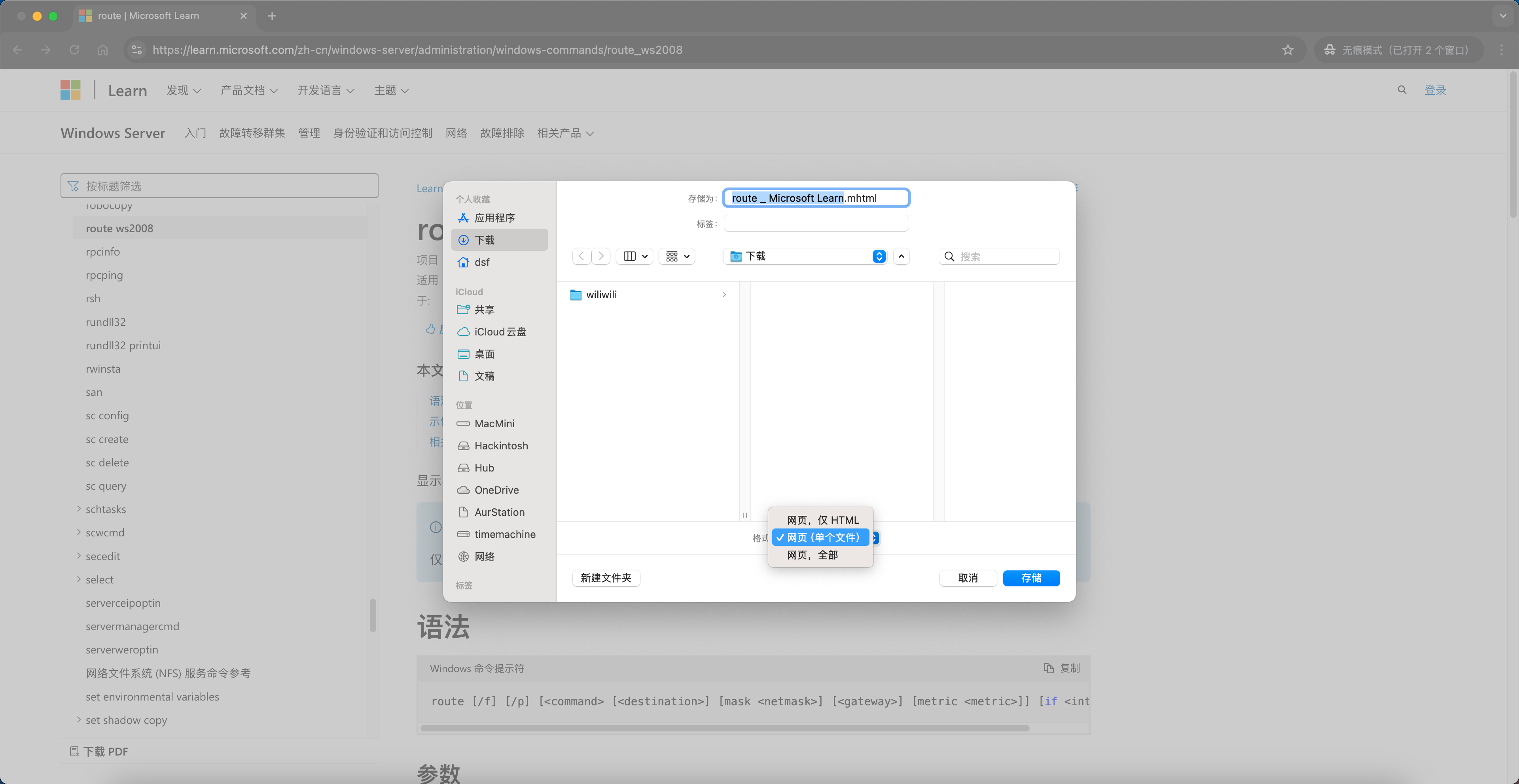
保存完成后可以看到文件,大小为 795.6 KiB。
1 | ls |
备份
设置好同步目录,将 .mhtml上传到 Git 仓库、云盘即可。
浏览
使用浏览器程序可以直接打开 .mhtml文件,进行浏览。如需搜索可使用 Everything工具搜索文件名,需要注意的是,我们无法直接检索到网页文件的文本内容。
方案二:SingleFile+Git 仓库+HamsterBase
需要部署自托管 docker 容器
HamsterBase。HamsterBase引入了标签系统和全文检索功能,方便了使用。在此过程中,我也相当于把离线网页文件保存了两份,一份在
Github,一份在HamsterBase里。
SingleFile官方仓库:https://github.com/gildas-lormeau/SingleFile
HamsterBase官方仓库:https://github.com/hamsterbase/hamsterbase
保存
使用 Chrome 扩展程序 SingleFile 进行保存离线网页。
点此访问 Chrome 应用商店安装扩展,安装完成后点击 SingleFile 图标即可保存网页。
SingleFile 生成的为单个 .HTML文件,默认情况下,会将网页文件保存到文件系统(也就是弹出对话框以选择保存位置)。
右键 SingleFile 图标,选择 选项,可以设置其保存位置,此处我使用 保存到Github,要用到个人访问令牌(Personal access tokens)。
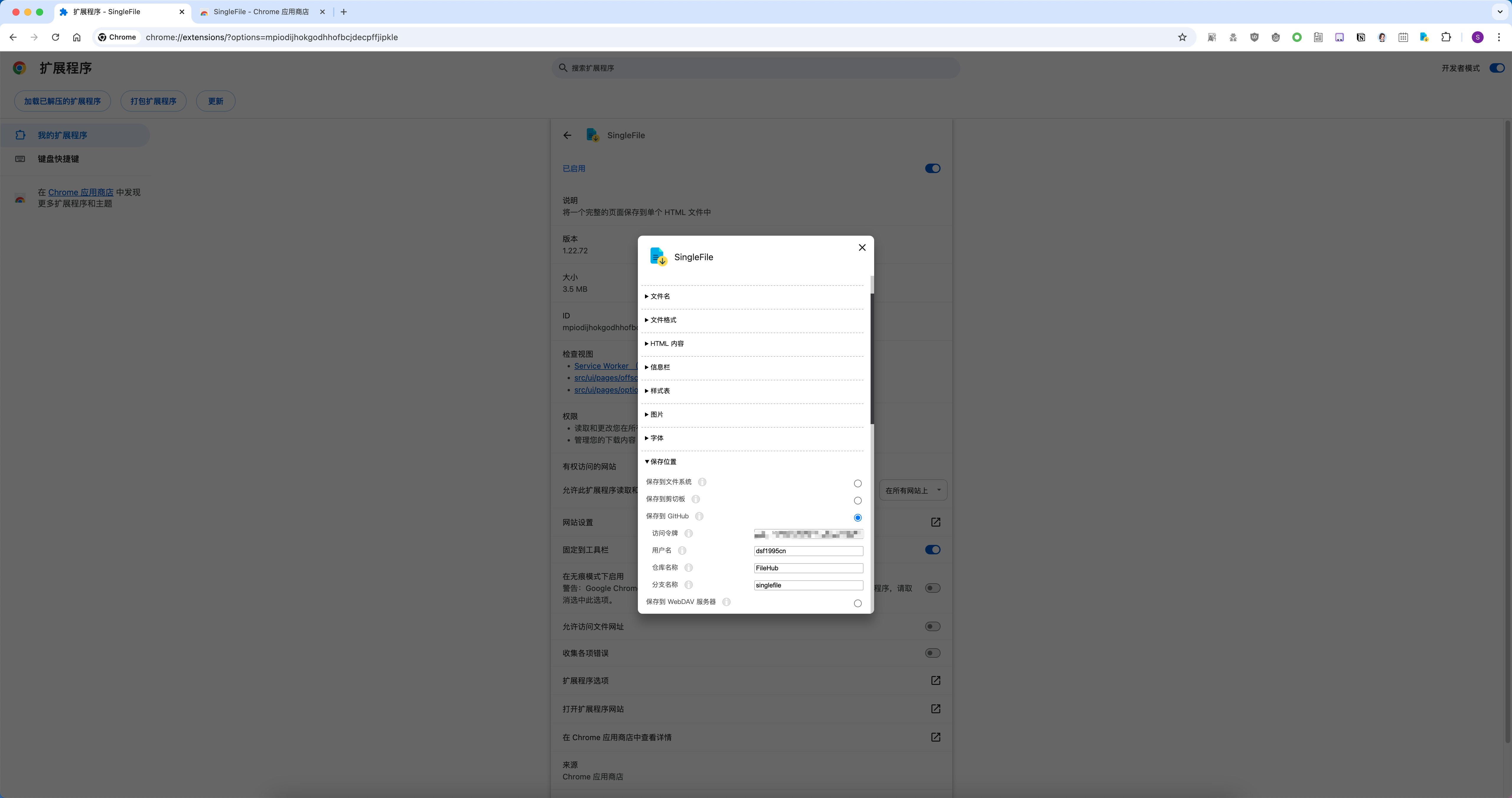
另外也可以使用 保存到WebDAV服务器,大家按需选择。
相比于 .mhtml文件,SingleFile 保存的 .html文件大了数倍。
1 | ls |
备份
保存到 Github 就已经拥有了备份。
浏览
使用 docker 部署 HamsterBase,点此参考官方文档。
部署完成后,打开其 WebUI,可以看到上传界面,这个界面适用于手动操作,了解即可。
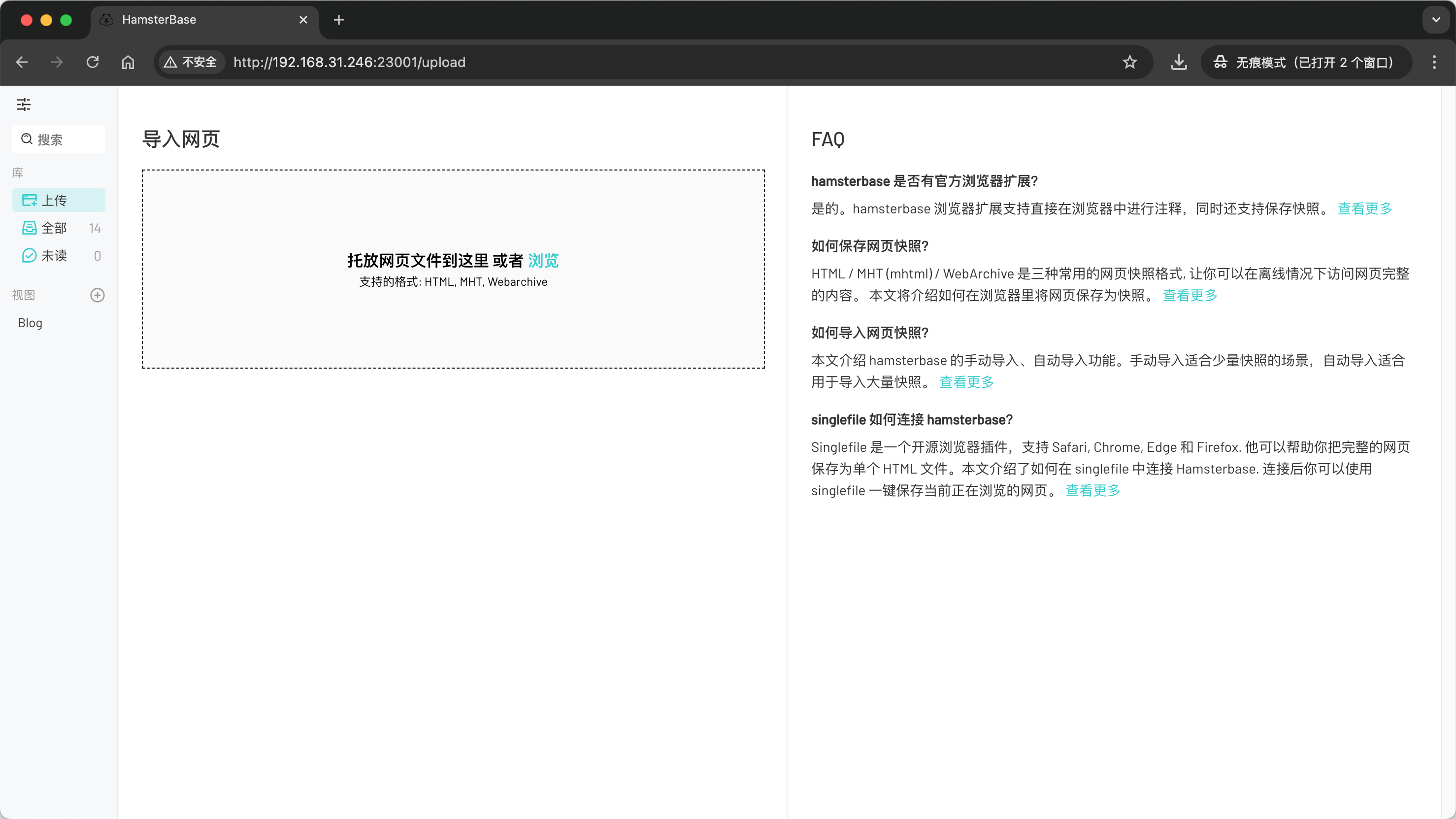
我们已经将网页文件保存到了 Github,如何将其导入 HamsterBase 呢?
查询官方文档得知,只要把网页文件放在 数据库的地址/workspace/inbox ,HamsterBase 会自动导入。
这里使用一个定时作业脚本完成,您可以将其运行在喜欢的运维平台上。我的同步周期为每 12 小时一次。
1 | 切换到本地Git仓库目录 |
同步完成后,在 HamsterBase 里即可使用标签、全文检索、访问原 URL 功能。
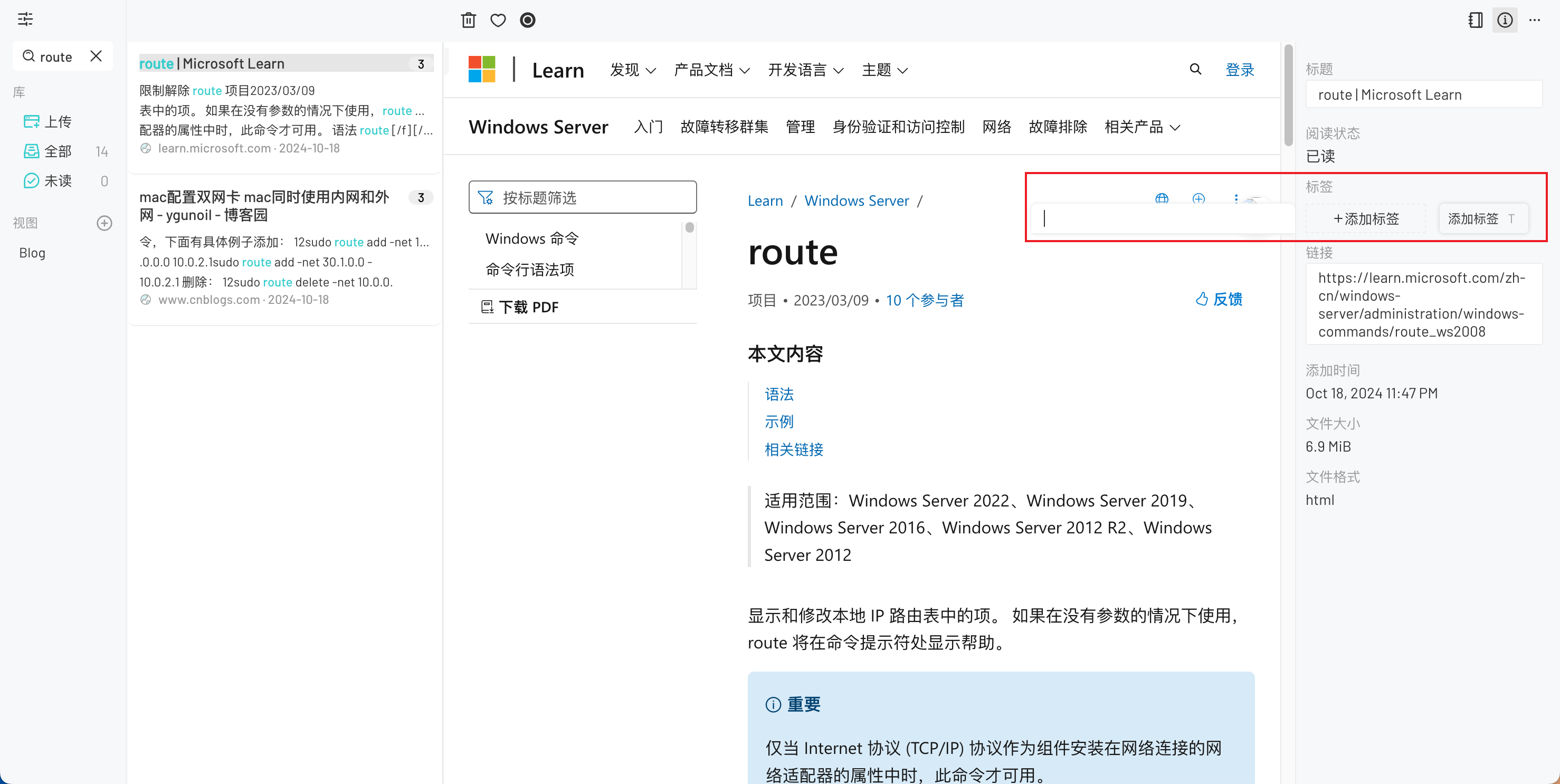
需要注意的是,每次都是使用全量拷贝以供 HamsterBase 自导导入,随着网页数量的增多,其导入速度肯定是会变慢的。这样做的主要原因是 HamsterBase 不支持批量导出原数据,所以我宁愿把数据保存两份:一份是在 Github 仓库里,以 .html文件的形式存在,作为异地备份;一份在 HamsterBase 中,方便使用。
总结
根据自身情况按需选择。
| 网页格式 | 优点 | 缺点 | |
|---|---|---|---|
| 方案一 | mhtml | 简单、保存文件小、更好的适用范围(浏览器) | 想使用标签,只能在文件名上做文章;无法检索离线网页内容 |
| 方案二 | html | 标签、全文检索 | 更高的部署难度;保存的网页文件过大 |
-EOF
查看最新版,请访问本文链接:https://blog.onehat.cn/p/517b.html
原创作品,转载请保留出处。